

Los mapas visuales de páginas web nos dan una idea de qué es lo que está pasando por detrás de las cortinas. Las páginas están normalmente diseñadas desde un punto de vista «humano», haciéndo énfasis en lo queremos que otra persona perciba al verlas y de forma que la organización espacial de los elementos que la componen hagan la información más accesible o, según los casos, predetermine a esa persona a fijar la atención en un elemento determinado.
La estructura de la información que contienen las páginas debería ser más artificial (o menos humana), ya que los estándares web tienden hacia una separación de contenido y código mediante el uso de etiquetas con valor semántico. Por simplificar mucho una historia muy larga, podríamos decir que la estructura de todas las páginas debería ser la misma:
- Título
- Encabecado 1: Contenido
- Subencabecado 1: Contenido
- Encabecado 2: Contenido
- …
- Encabecado 1: Contenido
Pero la realidad es que en ocasiones se utilizan esas etiquetas semánticas un poco fuera de su contexto, p. ej. se puede utilizar un subencabezado con una tipografía más llamativa que un encabezado. Una práctica muy común es utilizar contenedores «dummy» (sin ningún valor semántico, por ejemplo <div> y <span>) para ayudarnos a posicionar elementos en la página o dar mayor peso a determinados contenidos.
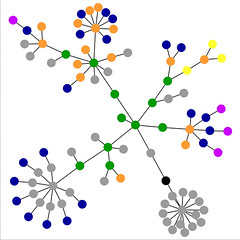
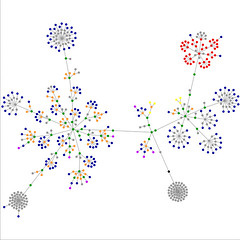
A la derecha podéis ver mapas visuales realizados mediante websitesasgraphs. La superior corresponde a la portada de esta web y la inferior a la portada del blog. El significado de los puntos es el siguiente:
azul: enlaces (la etiqueta <a>)
rojo: tablas (etiquetas <table>, <tr> y <td>)
verde: la etiqueta <div>
violeta: imágenes (etiqueta <img>)
amarillo: formularios (etiquetas <form>, <input>, <textarea>, <select>, y <option>)
naranja: párrafos, líneas nuevas y citas (etiquetas <p>, <br> y <blockquote>)
negro: la etiqueta <html>, el nodo raíz
gris: el resto de etiquetas
Me parece una curiosa forma de hacerse una idea del contenido de una página.